get_crossmatch_catalogues_column_map (function) ∞
-
get_crossmatch_catalogues_column_map(dbConn, log)[source] ∞ Query the sherlock-catalogues helper tables to generate a map of the important columns of each catalogue
Within your sherlock-catalogues database you need to manually map the inhomogeneous column-names from the sherlock-catalogues to an internal homogeneous name-set which includes ra, dec, redshift, object name, magnitude, filter etc. The column-name map is set within the two database helper tables called
tcs_helper_catalogue_views_infoandtcs_helper_catalogue_views_info. See the ‘Checklist for Adding A New Reference Catalogue to the Sherlock Catalogues Database’ for more information.Todo
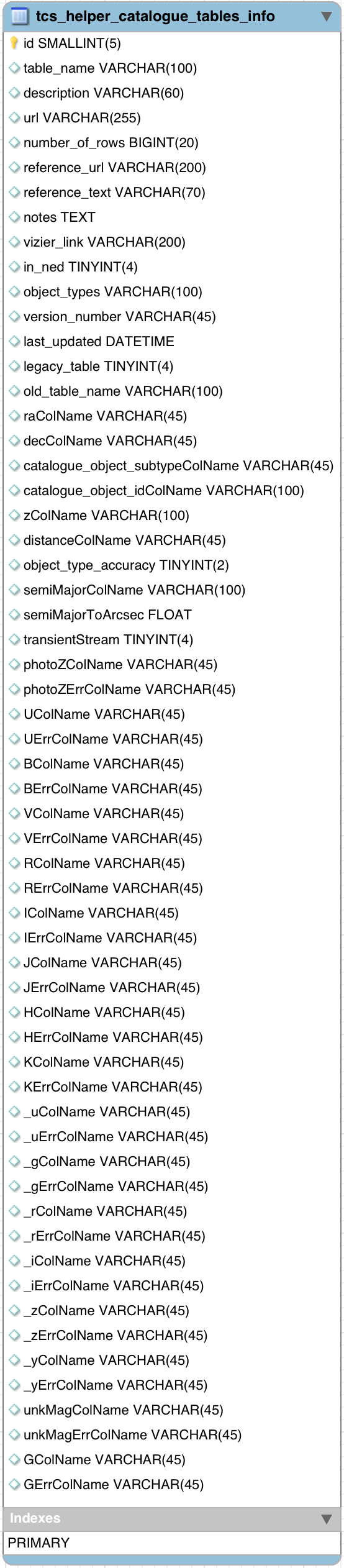
write a checklist for adding a new catalogue to the sherlock database and reference it from here (use the image below of the tcs_helper_catalogue_views_info table)
Key Arguments
dbConn– the sherlock-catalogues database connectionlog– logger
Return
colMaps– dictionary of dictionaries with the name of the database-view (e.g.tcs_view_agn_milliquas_v4_5) as the key and the column-name dictary map as value ({view_name: {columnMap}}).
Usage
To collect the column map dictionary of dictionaries from the catalogues database, use the
get_crossmatch_catalogues_column_mapfunction:from sherlock.commonutils import get_crossmatch_catalogues_column_map colMaps = get_crossmatch_catalogues_column_map( log=log, dbConn=cataloguesDbConn )